FM算法能够学习到原始特征的embedding表示
本文共 730 字,大约阅读时间需要 2 分钟。
FM算法是CTR预估中的经典算法,其优势是能够自动学习出交叉特征.因为这种特性,FM在CTR预估上的效果会远超LR.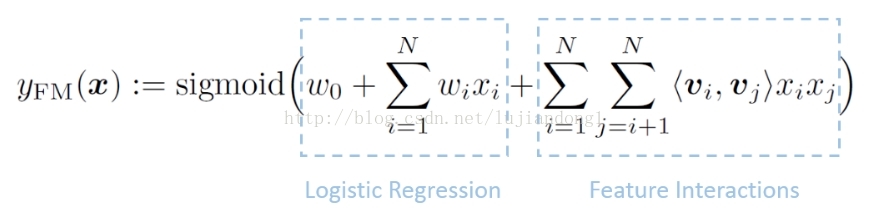
说明:通过FM的公式可以看出,FM自动学习交叉是通过学习到每个特征xi的向量表示vi得到的.比如说,对于field A,其特征有100w种取值,如果使用one-hot编码。那么,每个特征需要使用100w维特征表示.使用了FM算法学习之后,比如说使用vi的特征维度是10维.那么,每个特征就可以使用10维的向量表示.这个跟word embedding的思想是一致的.所以说,FM是embedding的一种方式.
我们需要将非常大的特征向量嵌入到低维向量空间中来减小模型复杂度,而FM(Factorisation machine)无疑是被业内公认为最有效的embedding model.第一部分仍然为Logistic Regression,第二部分是通过两两向量之间的点积来判断特征向量之间和目标变量之间的关系。比如上述的迪斯尼广告,occupation=Student和City=Shanghai这两个向量之间的角度应该小于90,它们之间的点积应该大于0,说明和迪斯尼广告的点击率是正相关的。这种算法在推荐系统领域应用比较广泛。
那我们就基于这个模型来考虑神经网络模型,其实这个模型本质上就是一个三层网络:
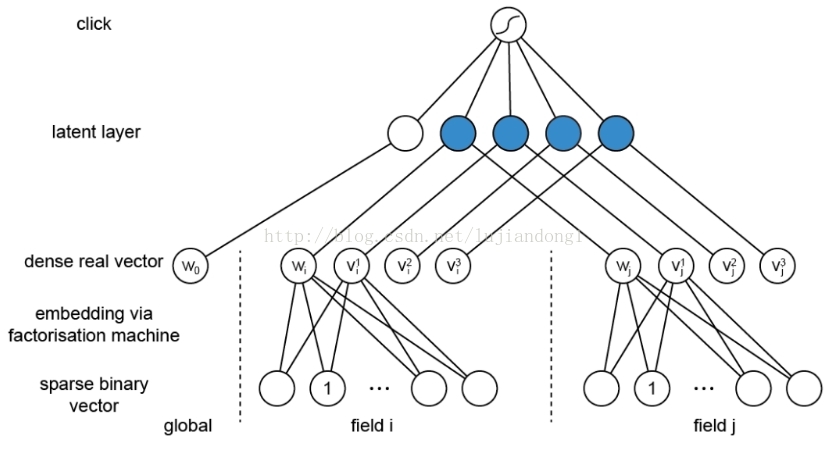
它在第二层对向量做了乘积处理(比如上图蓝色节点直接为两个向量乘积,其连接边上没有参数需要学习),每个field都
只会被映射到一个 low-dimensional vector,field和field之间没有相互影响,那么第一层就被大量降维,之后就可以在此基础上应
用神经网络模型。
使用了FM提取出每个特征的embedding表示。
你可能感兴趣的文章
java基本概念(二)
查看>>
简易的ATM机
查看>>
旧版本的ATM
查看>>
关于super()
查看>>
关于JAVA中GUI的使用
查看>>
494. Target Sum
查看>>
463. Island Perimeter
查看>>
TCP协议粗析
查看>>
653. Two Sum IV - Input is a BST
查看>>
spark rdd 和 DF 转换
查看>>
RDD 基础操作
查看>>
RDD基本操作(下)
查看>>
##########(python 解析参数方法 可用) Python optionParser模块的使用方法 #######
查看>>
org.apache.hadoop.io.compress系列1-认识解码器/编码器
查看>>
pyspark-combineByKey详解
查看>>
从原理到代码:大牛教你如何用 TensorFlow 亲手搭建一套图像识别模块 | AI 研习社
查看>>
FM算法详解
查看>>
谷歌推Tacotron 2,搞定绕口令,效果优于WaveNet
查看>>
Spark 2.1.0 入门:特征抽取–Word2Vec(Python版)
查看>>
[NLP] MXnet与TensorFlow的自然语言处理应用
查看>>